PIPS SPEAR-DE interface: From C to OpenCL
Sorry, this is a French document.
Nous débutons par une video permettant de visualiser les différentes étapes de la transformation d'une application C en code OpenCL a l'aide des outils PIPS, SPEAR-DE et PAR4ALL. Nous présentons ensuite le couplage des outils PIPS et SPEAR-DE, ainsi que les développements qui y ont été réalisés dans le cadre du projet OpenGPU. Ces informations sont extraites d'un des livrables du projet dont les auteurs sont Corinne Ancourt (Mines-Paristech), Remi Barrere (Thales Research & Technology), Michel Barreteau (Thales Research & Technology) et Francois Irigoin (Mines-Paristech).
From C to OpenCL by Rémi Barrère, on Vimeo.
1. Problématique
Le portage d’une application sur GPU suscite plusieurs questions:
- S’agit-il d’un code legacy ?
- Dispose-t-on d’outils de programmation ?
- Est-on tenu par des performances optimales ?
- Souhaite-t-on optimiser les kernels manuellement ?
- Est-on prêt à modifier nos habitudes de codage ?
- …
Dans le cadre du projet OPENGPU, il s’agit d’implémenter une application pour laquelle nous disposons des kernels, de deux outils principaux (PIPS et SPEAR) et essayons d’obtenir les meilleures performances possibles dans un temps raisonnable. Les kernels pouvaient être optimisés manuellement et ultérieurement par les experts métier pour atteindre les performances optimales.
Cela signifie que nous n’avons pas à ré-écrire l’ensemble du code, que l’outillage va nous permettre d’explorer rapidement plusieurs portages et que l’effort de débogage sera réduit grâce à l’écriture d’un code « hôte » correct par construction.
PIPS est un outil de transformation de code source-à-source automatique capable d’analyser un code C et d’en extraire des informations sur le parallélisme sous-jacent. Afin d’obtenir une analyse performante, PIPS requiert que le code obéisse à des règles de codage données (ex : pas d’arithmétique de pointeur).
SPEAR est un outil d’implémentation d’applications data-streaming sur architectures parallèles. La parallélisation est guidée graphiquement par l’expert. La génération automatique du code cible s’appuie sur le résultat de cette parallélisation spatio-temporelle (le code « hôte » généré automatiquement appelle le code des kernels).
Comme PIPS est capable d’analyser le parallélisme inhérent au code des kernels (tout comme l’application entière), on lui présente le code en question en suivant les règles de codage requises par PIPS. PIPS va ainsi fournir à SPEAR les paramètres de parallélisme avec lesquels l’expert pourra jouer dans SPEAR pour paralléliser son application.
2. Implémentation du Couplage PIPS / SPEAR
Le couplage PIPS / SPEAR s’effectue au travers d’un fichier applicatif XML (obéissant à une DTD fixée).
2.1. Implémentation PIPS
Cette interface avec SPEAR entre dans le cadre d'une chaîne de compilation visant les architectures GPU pour des applications de traitement du signal ou de traitement d’images.
Nous commençons par présenter le cadre applicatif et les règles de codage préconisées. Nous poursuivons avec une description globale de la modélisation de l’application, dont une partie est héritée du projet Ter@ops, et des extensions développées dans le cadre du projet OpenGPU.
2.1.1. Définitions
Une application au niveau spécification est formée d'un ensemble de tâches opérant sur des tableaux typés en fonction de paramètres. Ces tableaux sont déclarés et appelés tableaux réels en opposition aux tableaux formels qui sont les arguments des fonctions utilisées. Chaque tableau peut être lu ou défini par n'importe quelle tâche.
Une application peut donc être abstraite sous la forme d'un graphe orienté dont les nœuds sont des tâches et dont les arcs expriment l'existence d'un tableau défini par la tâche source et utilisé par la tâche destination (la tâche source pouvant être identique à la tâche destination). Une application est considérée comme correcte si ce graphe orienté est acyclique.
Les variables d'une application sont ses tableaux et ses paramètres de contrôle. Il n'y a pas de distinction sémantique formelle entre les deux types de variables, mais les tableaux sont les seules variables dont le placement a un impact à minimiser.
Les tableaux d'une application sont typés, nommés et dimensionnés numériquement. Deux tableaux différents ont des noms différents et vice-versa.
L'ordre des dimensions et donc des indices des tableaux n'est pas significatif. La définition de leur implantation en mémoire relève du placement de l'application.
Chaque tâche est un nid de boucles parallèles contrôlant l'application d'un traitement élémentaire utilisant un ou plusieurs tableaux en entrée et définissant un ou plusieurs tableaux en sortie, en fonction de paramètres de contrôle de l'application. Certaines tâches servent à calculer les paramètres de contrôle de l'application.
Un traitement élémentaire (TE) est vu au niveau spécification comme une boite noire ne pouvant pas faire l'objet d'une optimisation au niveau application parce qu'il est :
- implanté par un accélérateur câblé,
- ou bien implanté par un code disponible uniquement en binaire,
- ou bien implanté par une fonction C dont l'interface bloque les optimisations.
Les optimisations globales de traitements élémentaires nécessitent soit une restructuration de l'application pour, par exemple, fusionner deux traitements élémentaires successifs de l'application en un unique traitement, soit un inlining du code des traitements élémentaires dans le code de l'application.
L'optimisation locale d'un traitement élémentaire n'est possible que si l’on dispose du code source et que si ce code source accède aux tableaux par des expressions affines.
La plupart des traitements élémentaires sont des fonctions pures, mais certains peuvent avoir des effets de bord.
Un traitement élémentaire est caractérisé par les Motifs de ses paramètres formels, sa durée d'exécution, constante ou fonction de ses paramètres formels, par la taille de son code et par la taille des données temporaires qu'il utilise.
Une fonction de bibliothèque (ATE : traitement élémentaire ajustable) est une fonction qui applique un traitement élémentaire plusieurs fois, en principe au moyen de boucles parallèles. La spécification d'une fonction bibliothèque inclut donc d'une part celle du traitement élémentaire et d'autre part la manière dont ce traitement est ou peut être répété sur les tableaux paramètres formels.
2.1.2. Les règles de codage
Les fonctions C ne peuvent être modélisées que si elles respectent un certain nombre de règles de codage qui concerne le typage, les références, les appels de fonctions, les fonctions de bibliothèques et les traitements élémentaires :
2.1.2.1. Typage
Les types utilisés doivent faire partie des types connus du méta-modèle (structures de description de tableaux, …).
2.1.2.2. Références
L'arithmétique sur les pointeurs est interdite. Les pointeurs sont des constantes, éventuellement passées comme paramètre, ou en assignation dynamique unique au sein de la fonction.
Tous les tableaux devant faire l'objet d'une modélisation sont complètement dimensionnés (pas de dimensions linéarisées, pas de dimension non spécifiée). Les dimensions peuvent être symboliques.
Tous les tableaux devant faire l'objet d'une modélisation sont accédés avec des expressions d'accès affines. Si la fonction d’accès est non affine, le tableau est vu atomiquement.
Tous les objets qui ne sont pas identifiés comme des tableaux modélisables sont traités atomiquement comme des scalaires.
2.1.2.3. Appels de fonctions
Tous les paramètres formels modélisés, tableaux ou scalaires, sont soit lus soit définis.
Il est conseillé de passer les paramètres explicitement afin de simplifier les optimisations inter-procédurales et les analyses, mais il est possible d'utiliser des structures de contrôles non-récursives pour en réduire le nombre.
2.1.2.4. Fonctions de bibliothèques et traitements élémentaires
Les boucles de pavage de la fonction de bibliothèque (externes au Motif) sont en principe uniquement des boucles parallèles, parfaitement imbriquées, contenant tout le corps de la fonction, et ne créant pas de conflit dans les expressions d'indices.
Il n'y a pas de restriction sur la structure de contrôle du code du traitement élémentaire. Le traitement élémentaire peut faire appel à d'autres fonctions. Les appels récursifs, directement ou indirectement, sont interdits.
Si une fonction de bibliothèque appelle une autre fonction, cette autre fonction et toutes les fonctions qu'elle appelle sont traitées globalement via leurs effets au niveau de la fonction de bibliothèque.
2.1.2.5. Conclusion sur les règles de codage
Dans la mesure où ses types peuvent être modélisés, où tous ses paramètres formels sont soit lus soit complètement définis, où les pointeurs sont utilisés sans arithmétique, toute fonction C peut être modélisée.
2.1.3. L’interface
L'analyse du code de l'application et des fonctions de bibliothèque conduit à un fichier d'interface XML dont la structure est définie dans une DTD. Sa définition a évolué au cours du temps pour prendre en considération les besoins applicatifs et ceux des outils de placement.
2.1.3.1. Deux étapes
La génération des interfaces s'effectue en deux étapes. La première génère les interfaces pour toutes les fonctions de bibliothèque. Seules les informations issues des codes des fonctions de bibliothèque sont utilisées. Par conséquent, les tailles des tableaux, la taille des boucles sont renseignées de manière symbolique si tel est le cas dans le code. Les régions de tableaux sont des polyèdres convexes paramétriques.
La deuxième étape génère l'interface de l'application. Elle prend en considération toutes les informations issues du programme et des analyses sémantiques de PIPS. Ces informations renseignent, en plus des valeurs symboliques, les valeurs numériques prises par les différents paramètres au cours de l’exécution. Notons que les valeurs des paramètres réels des appels aux fonctions de bibliothèque sont ainsi données si l'analyse le permet.
2.1.3.2. Modélisation de l'application
Les deux figures suivantes présentent comment les différents éléments de la modélisation de l'application et des tâches se déclinent. Nous détaillons ici uniquement les attributs les plus importants de la modélisation et donnons quelques extraits correspondants de la DTD. Des exemples de ces modélisations sur l'application ABF de Thales seront ensuite présentés dans la section suivante.
Dans les deux figures suivantes, les attributs de couleur noire, représentent des informations qui sont directement accessibles dans le code du programme. Les éléments grisés représentent les informations nécessitant des analyses plus complexes et développées dans PIPS.
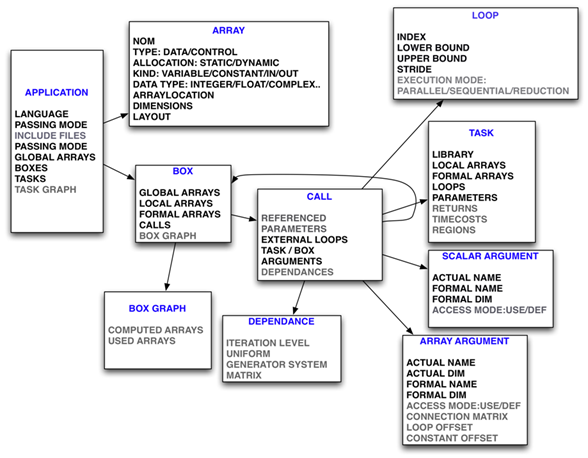
Modélisation de l'application
La définition de l'application contient les items suivants :
- le nom de l'application correspond au nom du fichier contenant le « main »
- le langage dans lequel le programme est écrit (Fortran ou C)
- le mode de passage des paramètres
- la liste des déclarations des tableaux globaux
- la liste des Box. Chaque Box contient un ensemble d'appels aux tâches.
Chaque tâche est un nid de boucles parallèles exécutant une fonction de bibliothèque ou faisant référence à une autre Box. - une liste de fonctions de bibliothèque
- le graphe des tâches
Modélisation d'un graphe de tâches
Le graphe des tâches exprime les dépendances de précédence entre les tâches.
Chaque tableau est défini par une seule tâche. Il dépend des valeurs de tableaux qui doivent être calculées précédemment.
Les nœuds du graphe de tâches sont définis par des éléments TaskRef. Les arcs du graphe sont définis implicitement par les noms des tableaux utilisés Needs ou définis Computes et explicitement de la destination vers la source (graphe de précédence).
Modélisation d'un appel à une tâche
L'appel à une tâche présente les éléments suivants :
- le nom de la tâche appelée ou de la Box contenant un ensemble d'appels,
- la liste des éléments de tableaux référencés par la tâche
- la liste des boucles externes à la fonction de bibliothèque,
- la liste des arguments.
Modélisation d'un argument
Un argument peut être un scalaire ou un tableau.
Chaque ArrayArgument précise la correspondance entre les paramètres réel et formel. Les attributs sont :
- le nom du tableau réel
- les dimensions du tableau réel (bornes inférieure et supérieure pour chacune des dimensions),
- le nom du tableau formel,
- les dimensions du tableau formel (bornes inférieure et supérieure pour chacune des dimensions),
- le mode d’accès du tableau : USE (tableau lu) ou DEF (tableau défini),
- une matrice de connexion C permettant de faire correspondre un élément du tableau formel à l’élément du tableau réel associé
- une matrice de pavage des boucles externes. Cette matrice est nécessaire lorsque les indices des boucles externes sont utilisés pour calculer l'offset de l'adresse du premier élément du tableau formel.
- un vecteur d'offset (adresse du premier élément du tableau formel dans le tableau réel).
2.1.3.3. Modélisation des traitements élémentaires
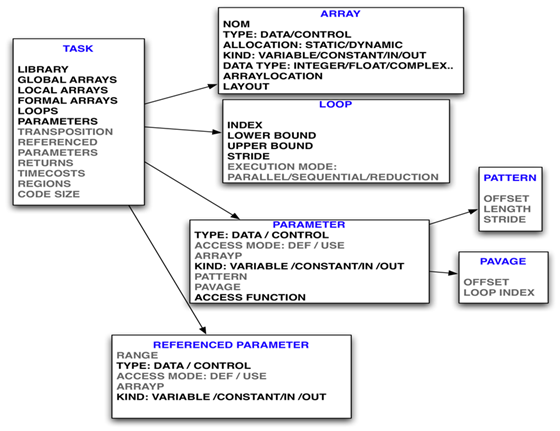
Modélisation d'une tâche
Une tâche est définie par ses attributs :
- le nom de la bibliothèque à laquelle elle appartient au cas échéant
- la valeur retournée
- une estimation de son coût d’exécution
- la déclaration des tableaux globaux de la tâche
- la déclaration des tableaux locaux de la tâche
- la déclaration des paramètres formels de la tâche
- la liste des tableaux référencés par la tâche et leurs caractéristiques
- les boucles de la tâche externes au Motif
- les paramètres formels de la tâche avec leur Motif lorsqu'il s'agit de tableau
- les Régions de tableaux
- une estimation de la taille du code
Modélisation d'une boucle
La modélisation d'une boucle précise :
- l'indice de boucle (unique pour un nid de boucles),
- le mode d’exécution (parallèle ou séquentiel ou une réduction),
- la borne de boucle inférieure,
- la borne de boucle supérieure,
- le pas (par défaut unitaire).
Modélisation d'un tableau
La modélisation d'un tableau énumère les éléments suivants :
- un nom,
- un Type permettant de distinguer les tableaux de données (DATA) et les tableaux de paramètres (PARAMETER).
- une Allocation précisant si le tableau est alloué statiquement (STATIC) ou dynamiquement (DYNAMIC).
- un Kind qui peut être VARIABLE (cas général d'un tableau modifié par l'application) ou CONSTANT (cas des constantes, pré-stockées éventuellement en mémoire) ou IN ou OUT (données qui nécessitent un traitement particulier éventuel, prise en compte de contraintes temps réel, stockage, …),
- un type parmi la liste suivante : INTEGER, FLOAT, COMPLEX, BOOLEAN, CHARACTER et la taille en octets d'une donnée ou INFINITY,
- pour chacune de ses dimensions :
- La borne inférieure
- la borne supérieure
Les bornes sont des expressions qui contiennent une partie symbolique obligatoire et une partie numérique optionnelle.
Les principales analyses de programmes de PIPS utilisées pour extraire ses informations sont les suivantes :
- Taille de code : estimation
- Régions convexes de tableaux
- Graphe de dépendances entre tâches
- Dépendances de tableaux dans les nids de boucles
- Détection des boucles parallélisables
- Détection des réductions
- Calcul des « Motifs » (approximation parallélépipédique des régions d'un tableau pour une itération donnée)
- Détection des corner-turns et calcul des matrices de transposition équivalentes
2.2. Implémentation SPEAR
L’utilité majeure de l’analyse fournie par PIPS est de pouvoir facilement importer dans SPEAR une application initialement écrite en C – qui peut donc être validée (compilée, exécutée et déboguée) – mais surtout d’extraire automatiquement des informations de parallélisme exploitables ultérieurement par SPEAR.
Cette analyse va fournir plusieurs types d’information qui vont pouvoir être utilisés par SPEAR. Il existe deux niveaux d’information qui peuvent être importés :
- Des informations concernant les fonctions de bibliothèques. Ces fonctions restent paramétrables (paramètres symboliques), permettant de les configurer en fonction de leur utilisation (taille des dimensions des tableaux, etc). L’objectif de cet import est de réutiliser des fonctions qui existent déjà dans un algorithme afin d’en définir un nouveau.
- Des informations concernant une application complète, c’est-à-dire les Tasks ainsi que toutes les autres informations nécessaires permettant leur appel successif (déclaration des tableaux, allocations, scheduling,…), qui va au final réaliser un algorithme complet. Cet algorithme réalisera le même traitement que l’application C analysée par PIPS. La plus-value de SPEAR est, dans ce cas, la possibilité de distribuer des tâches sur des processeurs élémentaires (parallélisme de tâches ou de données), avec tous les mécanismes que cela implique : communications, fusions de boucles, …
Les sections suivantes vont énumérer les informations utilisées dans SPEAR.
2.2.1. Fonctions de bibliothèque
2.2.1.1. Tasks
L’analyse de PIPS fournit des informations pour que SPEAR ait connaissance du fonctionnement d’une fonction élémentaire et puisse ainsi l’utiliser.
La première information est la présence ou non de boucles « for » à l’intérieur du corps de la fonction. La présence de boucles internes va soit permettre de moduler le nombre d’appels à la fonction dans une application, soit de le limiter, ou soit permettre de distribuer cette fonction sur plusieurs processeurs, selon le besoin.
La deuxième information est relative aux paramètres de la fonction C, dans leur ordre d’utilisation (correspondant au prototype de la fonction). Ces paramètres sont soit de type « Scalar », soit de type « Array ».
Dans le premier cas, il est nécessaire de connaître leur nom et leur type (int, float, …).
Dans le deuxième cas, cela nécessite nettement plus d’informations :
- le nom du tableau,
- son type d’accès (lecture ou écriture),
- le nombre et la taille de dimensions utilisées par appel,
- la manière de se déplacer dans un tableau à chaque itération si la fonction comporte des boucles internes.
Toutes les informations récupérées à ce niveau sont de type symbolique, ce qui permet d’utiliser la fonction dans d’autres applications que celle qui a été analysée par PIPS.
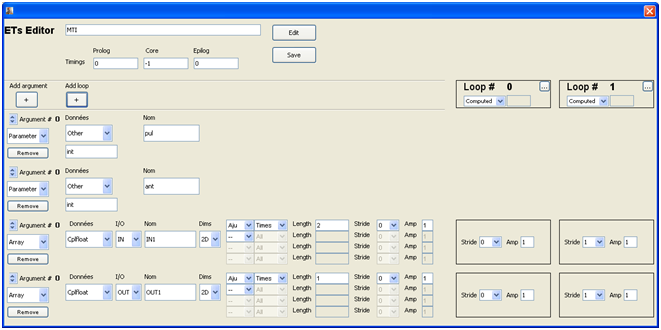
figure 1: exemple de Task importée dans SPEAR
2.2.1.2. Import des fonctions dans SPEAR
Dans SPEAR, il est possible de n’importer que les fonctions de bibliothèques d’une application, même si PIPS a analysé une application complète. Dans ce cas, il n’y aura aucun graphe d’application d’importé, mais la liste des tâches élémentaires utilisables sera complétée par les fonctions qui n’existaient pas encore (comme on travaille en C, c’est le nom de la fonction qui est déterminant).
En un simple clic de souris, l’import est réalisé:
figure 2: bouton d'import des fonctions de bibliothèque
L’intégralité des fonctions qui composent l’application Adaptive BeamForming est désormais disponible dans SPEAR :
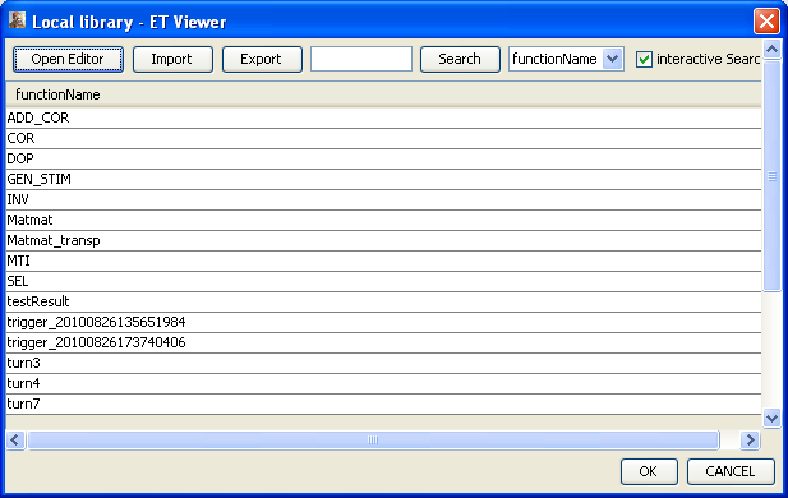
figure 3: Liste des fonctions de bibliothèque
2.2.2. Application complète
PIPS analyse une application complète : il est donc possible d’importer cette application sous SPEAR. Cet import peut avoir plusieurs fins :
- Avoir une représentation graphique afin d’avoir une meilleure compréhension de l’application,
- Pouvoir distribuer certains de ses calculs sur des processeurs parallèles,
- Pouvoir modifier le scheduling de l’application (réordonnancement, fusion de boucles, …)
Pour importer une application complète, il est important d’importer les tâches élémentaires qui la composent (cf. §2.2.1.1). Mais cet import seul ne suffit pas : il est nécessaire d’importer d’autres informations, que PIPS fournit également lors de son analyse. Ces informations sont décrites dans les sections suivantes.
2.2.2.1. IncludedFiles
PIPS analyse un programme complet, qui peut être un assemblage de plusieurs fonctions contenues dans plusieurs fichiers (.h et .c). Afin de pouvoir utiliser ces fonctions dans SPEAR et générer un code fonctionnel, il est important que l’analyse énumère les fichiers parsés par PIPS et fournisse une liste des fichiers à inclure lors de la compilation.
Exemple, pour l’application ABF, le contenu du fichier XML …
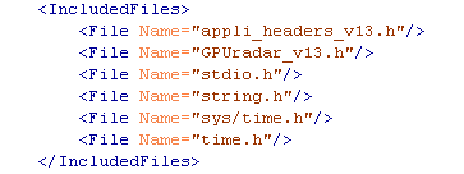
figure 4: #include dans le fichier XML
… se retrouve dans la liste des Global Definitions dans SPEAR :
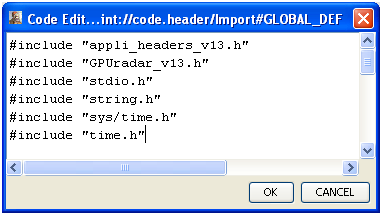
figure 5: #include dans SPEAR
2.2.2.2. GlobalArrays
PIPS fait une distinction entre les tableaux alloués en tant que variable globale (i.e. accessibles par toute fonction de l’application dont le body est situé dans le même fichier que la déclaration) et les tableaux alloués en tant que variable locale (i.e. accessibles uniquement dans le body de la fonction où le tableau a été déclaré).
SPEAR ne fait pas de distinction entre les tableaux alloués en variable globale ou locale, puisque l’atelier va créer un nouveau layout mémoire et potentiellement modifier l’endroit où un tableau est déclaré.
Dans l’application Adaptive Beam Forming, beaucoup des tableaux utilisés dans le flot de données sont des variables globales et quelques-uns sont des variables locales:
2.2.2.3. Box et BoxGraph
Une « Box » est un élément hiérarchique d’une application, qui est appelable comme une fonction élémentaire, mais qui ne fait que des appels à d’autres boxes ou à des fonctions élémentaires. Dans une application, le premier niveau est toujours la fonction « main() ».
Une box contient différents types d’information :
- les tableaux qui sont définis localement dans la box (avec leur type de données et leur taille par dimension),
- les différents appels aux tâches élémentaires (cf. §2.2.2.4) et/ou aux autres boxes d’un niveau hiérarchique inférieur,
- son BoxGraph correspondant.
Le « BoxGraph » est un élément essentiel dans une application de type « flot de données »: c’est dans cette structure que se trouve l’information de qui produit quoi, et qui consomme quoi à ce niveau hiérarchique.

figure 6: exemple de BoxGraph
SPEAR utilise les BoxGraph pour reconstruire son propre graphe d’application :
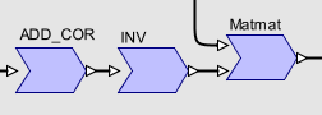
figure 7: graphe SPEAR correspondant au BoxGraph
2.2.2.4. Calls
Le « Call » est un appel à une fonction élémentaire ou Task (cf. §2.2.1.1), ou un nid de boucles répétant cette fonction élémentaire (boucle externe) sur différentes partie d’un tableau de l’application. C’est la partie du fichier qui permet de relier une tâche de traitement élémentaire (générique) à un tableau de données traité dans l’application (spécifique).
Si le call contient une ou plusieurs boucles externes, il faut préciser la borne inférieure et supérieure de chaque boucle.
Pour les arguments de type « scalaire », le call permet de donner une valeur numérique à un argument formel (symbolique).
Pour les arguments de type Array, les informations sont plus importantes. En effet, le call associe un tableau formel de la fonction élémentaire appelée avec un tableau global ou local de l’application. Mais comme ce tableau peut être très différent de celui attendu dans la Task : il peut contenir un nombre de dimensions supérieur à celui traité par la tâche élémentaire, être consommé dans un ordre différent que celui produit, avec une origine non nulle, etc... De plus, si le call contient des boucles externes, il faut expliciter le déplacement dans le tableau pour chaque boucle.
Toutes ces informations sont présentes dans le Call, sous forme de vecteur ou de matrice.
Un exemple avec le Call de la fonction MTI a ete donne dans la Figure 1. La fonction MTI consomme un tableau à deux dimensions, mais le tableau dans l’application en contient trois. Il y a donc une boucle externe qui va répéter 2000 fois l’appel à la Task MTI:

figure 8: exemple de boucle externe dans un Call
Cette fonction élémentaire MTI possède quatre arguments : deux de type « scalar », et deux de type « array ». La figure suivante montre que le Call de la fonction MTI possède également quatre arguments, et également l’association entre des valeurs symboliques (pul et ant), et leurs valeurs numériques dans le call (19 et 64).

figure 9: exemple de passage d'arguments dans un Call
Cette figure illustre également le fait que la fonction MTI consomme un tableau à deux dimensions (FormalDim à 2), et que le tableau utilisé lors du call est un tableau à trois dimensions (ActualDim à 3).
2.2.2.5. Mise à plat des niveaux hiérarchiques de l’application
Lors de l’analyse d’une application par PIPS, une box peut appeler une autre box, et cela se retrouve dans la hiérarchie du fichier de sortie généré.
SPEAR peut gérer des tâches de niveaux hiérarchiques différents. Cependant, afin de permettre une gestion optimale du scheduling, tous les niveaux hiérarchiques sont supprimés et l’application est mise « à plat ». Cela équivaut en C à une application qui ne contiendrait qu’une fonction main().
2.2.2.6. Import de l’application complète
SPEAR permet d’importer une application complète à partir du fichier généré par PIPS : non seulement les tâches élémentaires sont rajoutées à la bibliothèque de fonctions (comme décrit §2.2.1), mais le graphe d’application est intégralement reconstruit.
figure 10: import d'une application complète dans SPEAR
Cet import va permettre de reconstruire toutes les liaisons entre les « tasks » et les calls, entre les producteurs/consommateurs déclarés dans les BoxGraph et les tableaux alloués localement ou globalement, de retrouver les tours de boucles internes à la tâche ou externes, de manière à mettre en évidence les boucles parallèles et pouvoir les distribuer sur des architectures parallèles.
Après import dans SPEAR, on obtient le graphe d’application suivant :
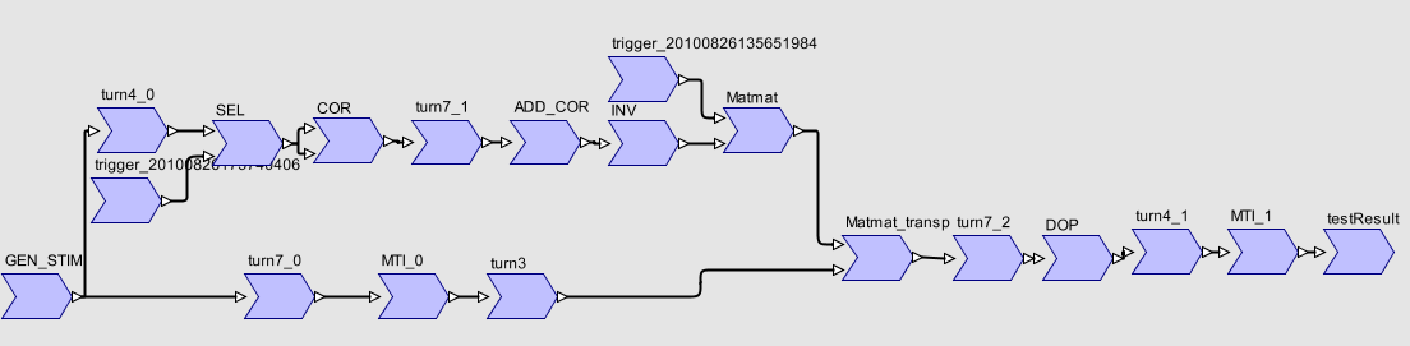
figure 11: application ABF importée dans SPEAR
2.2.2.7. Suppression des fonctions de réorganisation (corner-turns)
L’intérêt de cette chaine d’outillage est de permettre, à partir d’un code C fonctionnel, d’importer une application afin de pouvoir modifier son scheduling en la distribuant sur des architectures parallèles. Cependant, pour obtenir des résultats corrects, il est impératif en traitement du signal d’implémenter des fonctions de type « corner-turn ».
Un corner-turn réalise une réorganisation d’un tableau multidimensionnel de manière à toujours présenter le tableau qui a été produit dans l’ordre dans lequel il doit être consommé. L’atelier SPEAR, lorsqu’il génère du code, peut utiliser des fonctions de réorganisation de tableaux multidimensionnels optimisés pour l’architecture cible.
S’il est nécessaire d’avoir des corner-turns dans l’application en entrée de PIPS afin de pouvoir valider les résultats, il est donc inutile d’écrire des fonctions très élaborées puisque SPEAR peut en utiliser de plus performantes.
Il est donc possible de préciser à PIPS, dans l’application, que certaines fonctions ne font que de la réorganisation de données, et qu’il est par conséquent inutile d’importer ce genre de fonction. PIPS crée alors, pour la « Task » dans le fichier XML, une matrice de transposition qui correspond à la transformation dimensionnelle qu’effectue le corner-turn.
Voici un exemple de corner-turn annotée de manière à être ignorée dans l’import : un simple //CORNERTURN suffit :

figure 12: fonction "corner-turn" annotée
Cette matrice de transposition est utilisée par SPEAR pour déterminer lors du mapping, qu’un corner-turn est nécessaire à certains endroits de l’application, et connaître les dimensions à interchanger. Si deux tâches de réorganisation se succèdent, SPEAR va également reconstruire une matrice composée équivalente à ces transformations successives.
Le graphe d’application sans les tâches de réorganisation est donc simplifié et devient :
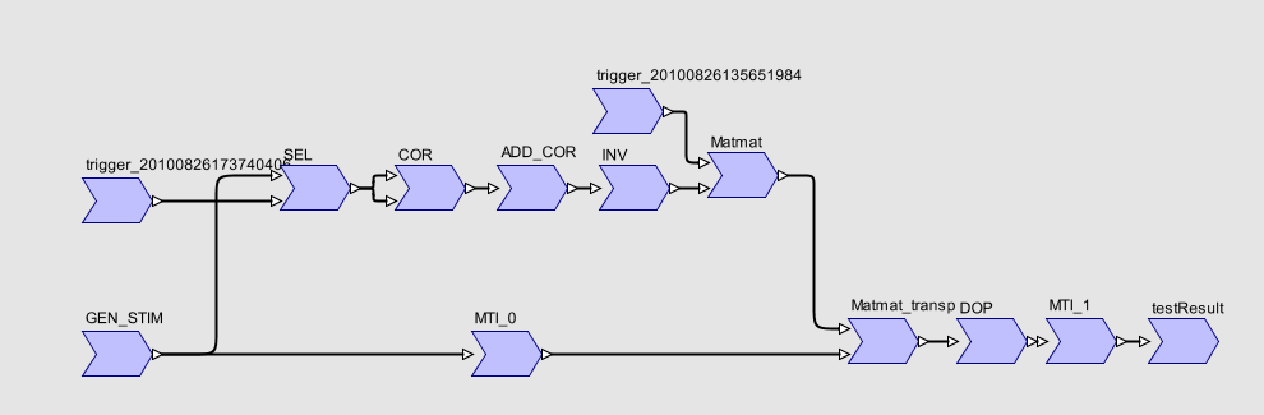
figure 13: application ABF sans corner-turn importée dans SPEAR
Même si les corner-turns ont été supprimés du graphe, SPEAR possède néanmoins toutes les informations nécessaires pour générer du code fonctionnel.
2.2.3. Validation de l’importation
Il existe un moyen efficace de vérifier que l’import dans SPEAR est correct. Il suffit de déployer l’application importée sur une architecture monoprocesseur (ici un processeur x86), de générer le code associé et de vérifier que toutes les étapes se déroulent correctement : import, mapping, génération de code et exécution.
Si l’intégralité du process se déroule sans problème et que les résultats obtenus sont les mêmes que ceux escomptés, c’est que l’import est correct.
Le process complet est donc celui-ci :
- Ecriture d’une application C qui compile et s’exécute
- Analyse par PIPS de cette application
- Création d’un fichier XML élaboré à partir de cette analyse
- Import par SPEAR de ce fichier XML
- Mapping sur une architecture supportant le langage C (parallèle ou non)
- Génération de code à partir du graphe
- Compilation du fichier généré et des fonctions de bibliothèques que PIPS a analysées
- Exécution et vérification que les résultats sont identiques à l’application C initiale
2.3. Exemples
2.3.1. Analyse d’une application
Dans l’exemple d’application ci-dessous, PIPS est capable d’analyser les fonctions et procédures appelées, d’identifier pour chacune d’entre elles ses tableaux d’entrée et de sortie, selon quelles dimensions ils sont parcourus en fonction du nid de boucles englobant.

On peut ainsi construire tout ce qui constitue une application SPEAR :
2.3.2. Analyse d’un kernel
On s’intéresse ici au kernel COR relatif à l’étape de corrélation. Le code ci-dessous est analysé par PIPS qui détecte les dépendances pour chaque élément de tableau.
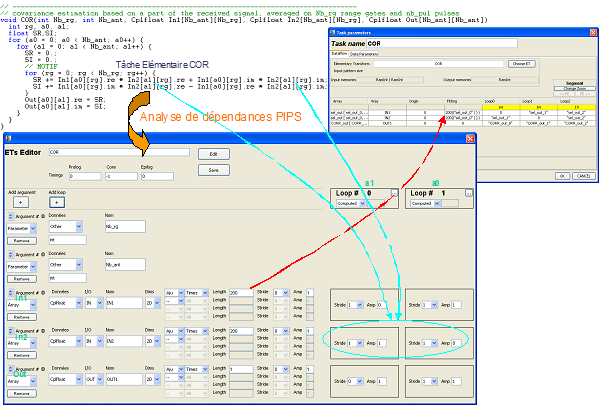
Ainsi PIPS détecte qu’il faut lire 200 éléments de tableau de chaque tableau d’entrée In1 et In2 pour écrire un élément de tableau Out. PIPS calcule aussi le « direction » et les sauts de parcours dans ces tableaux pour chaque boucle considérée.
2.3.3. Complémentarités des outils
On peut associer le couple PIPS/SPEAR avec l’outil Par4All de HPC Project. En effet, une des fonctions de cet outil permet d’analyser une fonction C (Task) et de produire le kernel OpenCL associé. Une association de trois outils aux caractéristiques différentes mais complémentaires permettrait, avec un effort minimum de porter une application sur GPU.
Pour cela, le process de portage serait :
- Ecrire une application C respectant les règles de codage de PIPS / Par4All,
- Analyser cette application par PIPS afin de créer un fichier XML correspondant,
- Importer ce fichier dans SPEAR,
- Utiliser les fonctionnalités de SPEAR pour déterminer quelles fonctions doivent être exécutées sur CPU ou sur GPU,
- Une fois la sélection réalisée, à travers SPEAR appeler automatiquement Par4All, en lui passant les bons arguments afin de transformer du code C en code OpenCL efficace,
- Utiliser SPEAR pour créer les communications CPU ó GPU,
- Générer du code afin d’exploiter au mieux le GPU (bande passante PCIe, gridification, …) comme le CPU (directives OpenMP, optimisation du layout mémoire, …),
- Compiler le code et en permettre l’exécution si l’utilisateur le souhaite.
Ce scénario permet d’obtenir rapidement (car réalisé de manière automatique) un code fonctionnel et efficace sur GPU, avec une intervention humaine limitée.
3. Génération de code OpenCL depuis SPEAR
3.1. Introduction
Le portage d’une application existante (en C) en vue de son exécution sur GPU peut se faire de différentes manières :
- manuellement, par un programmeur,
- automatiquement, par des outils qui permettent de passer d’un code C vers un langage de programmation adapté aux GPUs (OpenCL, CUDA,…),
- assisté par l’outil SPEAR, interne Thales.
La première méthode nécessite un développeur possédant une bonne connaissance de l’architecture du GPU cible et du langage à utiliser. Si la programmation parallèle se répand au fur et à mesure que les architectures parallèles s’imposent au quotidien, la programmation sur architecture many-core reste encore hermétique. De ce fait, les développeurs ayant les connaissances nécessaires (langage + architecture) sont encore rares.
La deuxième méthode peut sembler la plus séduisante : le GPU peut se programmer en langage C, à l’aide de directives et des outils appropriés (HMPP de CAPS Entreprise, ou Par4All de Silkan par exemple) qui vont générer de manière automatique et transparente du code exécutable sur GPU.
Malgré l’intérêt de s’appliquer à un code existant complet, tout n’est pas parfait dans cette méthode :
- le code C existant nécessite une réécriture préalable pour respecter les règles de codage permettant à ces outils de pouvoir l’analyser (première étape indispensable à toute génération automatique),
- il faut bien connaître l’outil, les différentes directives, et de nombreuses itérations sont nécessaires pour obtenir de bonnes performances (plusieurs semaines à plusieurs mois selon CAPS Entreprise),
- l’outil réalise une génération de code « générique » : en effet l’architecture matérielle cible n’est pas connue et le code généré ne sera donc pas aussi efficace que du code spécifique réalisé manuellement.
La troisième méthode consiste à s’appuyer sur un outil (SPEAR) de parallélisation semi-automatique à partir d’une modélisation de haut niveau (qui ne se positionne donc pas dans la catégorie d’outils précédente), mais qui propose plutôt d’automatiser un bon nombre de points qui sont fastidieux à implémenter manuellement, mais pourtant indispensables pour obtenir de bonnes performances. Cela ne laisse au développeur que le soin de développer / optimiser une bibliothèque de fonctions, qui s’enrichira au fur et à mesure que ces fonctions seront réutilisées par la suite dans différentes applications.
En résumé, un procédé semi-automatique qui vise les performances d’une méthode manuelle, tout en améliorant la productivité.
NB : on s’intéresse ici au portage d’une application en OpenCL, langage choisi en tant que standard normalisé qui peut maintenant être exécuté sur différentes plateformes parallèles (ex : Nivdia, AMD, Intel). Néanmoins, la génération de code, les procédés et optimisations décrits dans la suite pourraient tout à fait s’appliquer en l’état ou être adaptés aisément au langage CUDA.
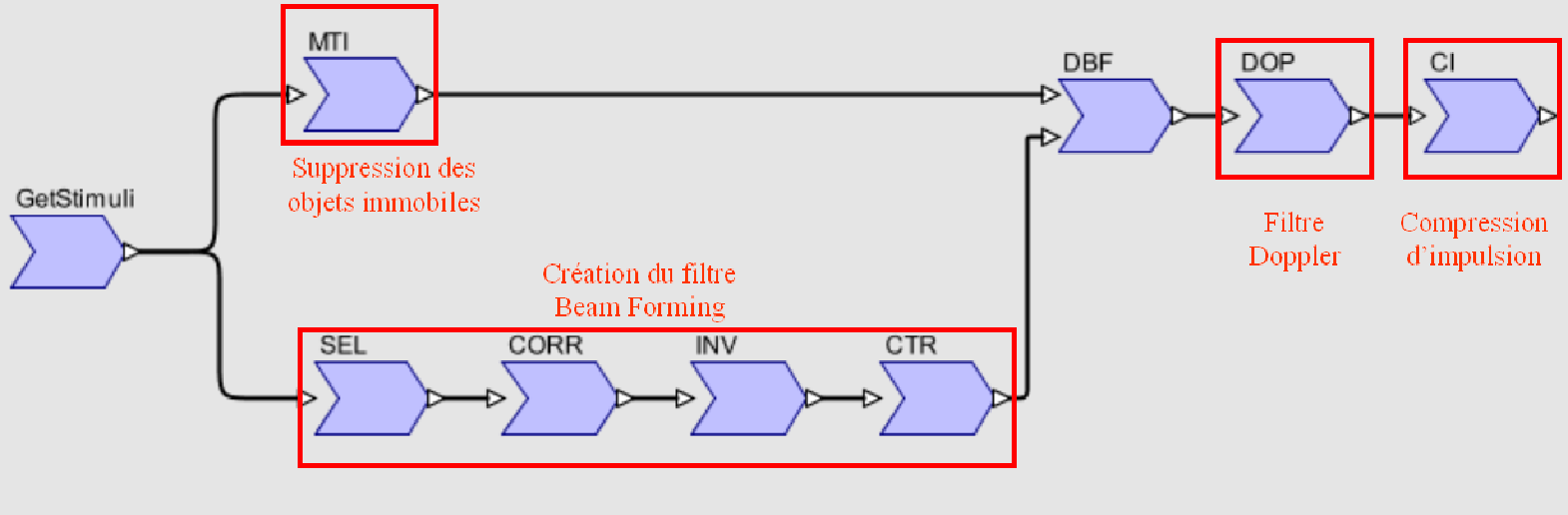
3.2. Notion de « host » et « kernels »
Un programme OpenCL est réalisé en deux parties : une partie exécutée par le processeur central (CPU) qui joue un rôle de chef d’orchestre, et une partie réalisée par le périphérique accélérateur, comme par exemple une carte graphique.
Le code qui est exécuté sur le CPU est appelé le code « host ». Il sert à gérer les communications de la mémoire du PC vers la mémoire embarquée de l’accélérateur, à lancer des calculs sur ce même accélérateur, puis à récupérer les résultats vers la mémoire de l’ordinateur. Aucune action n’est possible sur l’accélérateur sans cette partie de code.
Le code exécuté sur GPU (ou tout autre périphérique OpenCL) est composé de plusieurs fonctions distinctes qui sont appelées le plus souvent séquentiellement, pour réaliser une fonction de calcul spécifique (FFT, multiplication matrice/vecteur, matrice/matrice, etc…). Ces fonctions de calcul déporté sont appelées « kernels ».
3.3. Génération de code « host »
Avant toute tentative d’automatisation, il est important de savoir comment programmer une architecture manuellement pour obtenir de bonnes performances.
L’ordre d’exécution d’une application OpenCL se décompose en plusieurs étapes :
- <Host> : allocation des ressources sur le GPU,
- <Host> : compilation des kernels,
- <Host> : transfert des données de la mémoire centrale vers la mémoire du GPU,
- <Host> : appel d’un ou plusieurs kernels avec les bons arguments (tableaux en entrée, tableaux en sortie, paramètres, etc…),
- <GPU> : exécution du / des kernels appelés sur les processeurs parallèles,
- <Host> : transfert de la mémoire GPU vers la mémoire centrale,
- <Host> : libération des ressources utilisées du GPU.
Pour qu’un calcul s’exécute sur GPU, tout cet enchainement est nécessaire, et reste incompressible, et ce quel que soit le nombre de kernels utilisés. De plus, chaque appel à un kernel s’accompagne d’un nombre de lignes au moins égal au nombre d’arguments de ce kernel : plusieurs lignes pour répartir le calcul sur les processeurs parallèles du GPU, plus une ligne pour l’appel au kernel lui-même.
3.3.1. Code commun à toutes les architectures
Le langage OpenCL est relativement verbeux (dû à son support par un grand nombre d’architectures parallèles aux caractéristiques parfois très différentes). Par conséquent l’écriture d’un code OpenCL côté « host » comporte un grand nombre de lignes (nettement plus qu’un code C). Par exemple, pour une application donnée (cf ABF dans WP4a-d), la fonction main() passe de 50 lignes en C à 280 lignes en OpenCL, l’appel à une fonction de 1 ligne en C à entre 7 et 15 lignes en OpenCL.

Figure 14: exemple de code OpenCL : appel à un kernel
Comme décrit précédemment, l’utilisation d’un périphérique OpenCL nécessite des déclarations, allocations, la récupération du code des kernels et leur compilation, ainsi que toutes les mécaniques afin de mettre en œuvre des calculs sur GPU. Même si ce code est souvent répétitif, il devient contraignant de devoir l’écrire à la main, en particulier pour des applications relativement longues.
De plus, il ne faut pas négliger le fait qu’un code « host » bien écrit est essentiel pour obtenir de bonnes performances sur GPU. Ecrire cette partie de code est laborieux et peut prendre beaucoup de temps à un développeur (OpenCL est très verbeux), mais c’est une partie à ne surtout pas négliger si l’objectif est d’atteindre de bonnes performances.
C’est essentiellement sur cette partie « host » que l’outil SPEAR peut générer de manière automatique du code et faire gagner en productivité. A partir d’un graphe d’application saisi initialement, l’outil SPEAR permet de sélectionner de manière graphique (drag & drop) les fonctions qui vont être exécutées sur le CPU, et celles qui vont être exécutées sur le GPU. Quelques clics de souris permettent de créer les communications entre la mémoire centrale du PC et la mémoire embarquée du GPU (appelée mémoire globale).
Dans cette figure, chaque boite grise correspond à une tâche de calcul, c’est-à-dire une fonction « élémentaire », sélectionnée dans une bibliothèque de fonctions, qui va être exécutée un certain nombre de fois afin de consommer l’intégralité des données en entrée. Le terme de « boucles imbriquées » est utilisé pour décrire la structure de chaque tâche.
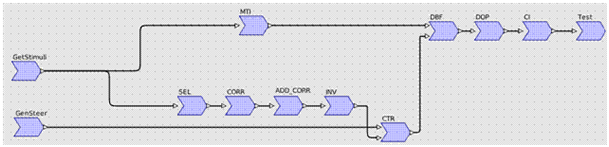
Figure 15: graphe SPEAR d'une application fonctionnelle
Dans la Figure 16, la ressource de calcul utilisée pour exécuter les fonctions de l’application est représentée par une couleur. Ainsi les tâches de calcul en rouge seront exécutées sur le CPU, en orange sur le GPU et en vert, de nouveau par le CPU. Les tâches symbolisées par des flèches et possédant deux couleurs représentent les communications entre CPU et GPU. Enfin, les tâches monochromes avec une flèche en forme de L représentent des fonctions de réorganisation de données. En effet, comme les fonctions sont écrites pour consommer et produire des données multidimensionnelles dans un certain ordre, il est parfois nécessaire de modifier l’ordre de ces dimensions afin que l’application soit fonctionnelle. En traitement du signal, cette réorganisation est appelée « corner-turn ».
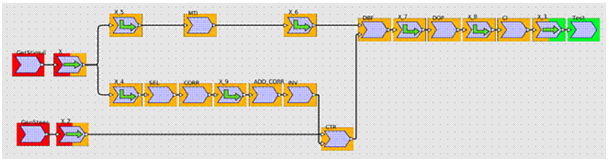
Figure 16: application déployée sur une architecture
A partir des informations récupérées à partir de cette application déployée sur des ressources de calcul, SPEAR est capable de générer le code « host » de manière automatique. Les sections suivantes décrivent de manière détaillée le code ainsi généré.
3.3.1.1. Code fonctionnel nécessaire
Cette partie de code générée automatiquement par SPEAR ne présente pas de difficulté particulière. Tout développeur qui programme en OpenCL doit obligatoirement écrire ce qui suit pour pouvoir exécuter du code sur GPU :
- déclaration des contextes de travail, des périphériques utilisés,
- déclarations d’au moins une « command queue » pour que le host puisse piloter le GPU,
- déclaration des programmes à compiler pour le GPU,
- déclarations des kernels qui vont être exécutés sur GPU,
- déclaration des tableaux utilisés sur GPU,
- récupération des informations déclarées (contextes, devices, queues, programme, kernels),
- allocation des tableaux.
A la fin de l’application, il faut libérer proprement toutes les ressources utilisées par le programme. Cette liste (non exhaustive) montre la lourdeur de la mise en œuvre du langage OpenCL, pourtant nécessaire avant toute exécution d’un calcul sur GPU. Grâce à SPEAR, cette lourdeur est épargnée au développeur qui peut se concentrer sur d’autres points plus importants.
3.3.1.2. Code asynchrone
Une manière de réaliser un programme sur GPU est de le programmer de manière synchrone : les instructions sont exécutées séquentiellement, et il faut attendre la fin d’une instruction afin de pouvoir exécuter la suivante (barrière de synchronisation implicite). Cette manière de programmer est la plus évidente pour un programmeur, puisque cela ressemble fortement à tout langage séquentiel, et c’est une manière efficace de s’assurer que l’ordre de précédence est respecté.
Cependant cette méthode présente certains désavantages :
- le temps d’exécution sur GPU n’est pas optimal,
- le CPU ne peut pas effectuer d’autres tâches pendant que le GPU travaille.
En effet, chaque travail sur GPU doit attendre que le précédent soit terminé avant d’être envoyé, ce qui rajoute un overhead à chaque fois. De plus, les barrières de synchronisation sont coûteuses en nombre de cycles.
Une solution pour améliorer ces points est d’écrire du code « asynchrone ». C’est-à-dire que le travail à réaliser sur GPU (communications et calculs) est préparé à l’avance, sur le CPU, dans une file de commande (le terme « command queue » est utilisé en OpenCL) ; puis cette command queue est envoyée au GPU qui va pouvoir travailler de manière autonome. Le CPU reste libre d’effectuer ensuite des calculs de son côté. Seul le moment où le CPU va vouloir utiliser des résultats produits par le GPU nécessite une barrière de synchronisation.
En asynchrone, pour que le code soit correct, il faut s’assurer que l’ordre de précédence est respecté. OpenCL fournit des « events » afin de synchroniser les différentes tâches entre elles. Ces events sont passés en arguments des différents appels passés dans la command queue afin de s’assurer que chaque tâche (calcul ou communication) ne commence que lorsque la tâche précédente (calcul ou communication) a terminé et que les données nécessaires sont bien présentes en mémoire.
SPEAR DE génère par défaut du code asynchrone, ce qui signifie que :
- les communications et calculs sont placés dans une command queue de manière non bloquante,
- les events sont positionnés de manière à s’assurer que le scheduling est correct,
- les barrières de synchronisation sont placées au bon endroit pour synchroniser le CPU et le GPU,
- le CPU n’est pas bloqué pendant que le GPU travaille (sous réserve que le CPU n’a pas besoin des résultats produits par le GPU).
La Figure 17 montre la différence de fonctionnement entre une programmation synchrone et une programmation asynchrone.
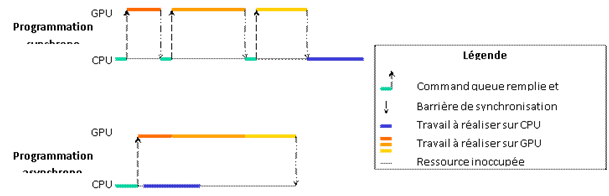
Figure 17: programmation synchrone et asynchrone
Un autre intérêt d’utiliser du code asynchrone est que le langage OpenCL permet, d’après ses spécifications, un fonctionnement en mode « out of order ». Bien évidemment, ce fonctionnement reste dépendant de l’implémentation inhérente à chaque architecture. Cependant, lorsque cette fonctionnalité est mise en œuvre, elle permet d’avoir potentiellement un gain de temps lors de l’exécution.
Le principe est le suivant : une tâche Tn est placée dans une command queue, puis une tâche Tn+1 vient ensuite. Si le mode de fonctionnement « out of order » n’est pas actif, Tn s’exécutera toujours avant Tn+1. Dans le cas contraire, si les conditions de précédence de Tn ne sont pas remplies, mais que celles de Tn+1 le sont, cette dernière commencera avant Tn, alors qu’elle a pourtant été placée après Tn dans la command queue.
Ce mode de fonctionnement nécessite de travailler de manière asynchrone, mais également impose un ordre de précédence de chaque tâche afin que l’ordonnancement soit correct.
Le code généré par SPEAR utilise les events de façon à ce que le mode « out of order » puisse être utilisé tout en s’assurant, en forçant les ordres de précédence, que l’application produise les bons résultats.
3.3.1.3. Optimisation des transferts de données
Dans les applications temps réel étudiées au cours du projet OpenGPU, il apparaît qu’une partie non négligeable du temps d’exécution d’une application sur GPU correspond en fait aux communications, c’est-à-dire au transfert des données de la mémoire du PC vers la mémoire du GPU (appelée mémoire globale), ou le transfert dans le sens contraire.
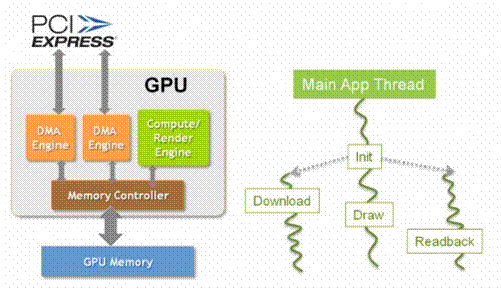
Figure 18: utilisation des DMAs
Ces transferts peuvent être optimisés en utilisant directement le contrôleur mémoire du GPU, plutôt que le GPU lui-même. Ce transfert est appelé DMA, pour Direct Memory Access. Cet accès direct à la mémoire permet de transférer directement de la mémoire du PC vers la mémoire globale du GPU, sans charger les ressources de calculs de ce travail. Pour cette optimisation, il faut que la mémoire utilisée pour stocker les données dans la mémoire du PC soit adressée directement dans la mémoire physique (c’est-à-dire non protégée par le système d’exploitation, non paginable, etc…). En effet le contrôleur DMA ne peut travailler qu’avec un accès direct à la mémoire avec des adresses physique - ou bien, sur les systèmes les plus récents, avec des adresses de périphérique (device addresses).
Cette mémoire est appelée « pinned memory ». L’utilisation de cette mémoire lors de transferts de la mémoire du PC vers la mémoire globale du GPU (via le bus PCI Express) a un impact direct sur la bande passante atteignable lors des transferts. Par contre son utilisation dans les autres cas n’a aucun intérêt.
La figure ci-dessous (mesures expérimentales sur GeForce GTX 480) montre la bande passante atteinte en fonction de la taille du transfert (abscisse) et l’utilisation ou non de la pinned memory :
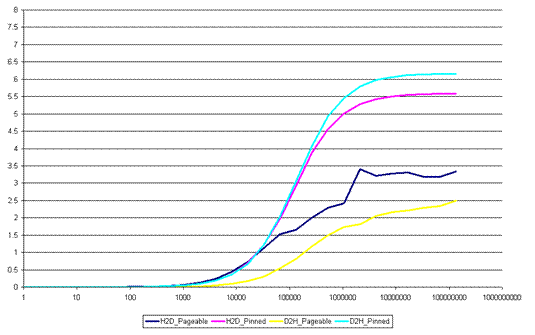
Figure 19: impact de la pinned memory dans les transferts (GTX 480)
La conclusion de ce graphique est qu’il vaut mieux effectuer des transferts de grosse taille (> 1Mo), et surtout absolument utiliser la pinned memory sous peine de voir la bande passante saturer à 3 Go/s au lieu des 6 Go/s possibles (8 Go/s théoriques sur un bus PCIe 2.0 16x).
Par contre, du fait qu’elle n’est pas paginable par le système d’exploitation, l’utilisation de trop de pinned memory dans un programme peut conduire à l’instabilité du système, ou à l’impossibilité de l’allocation mémoire et donc de l’exécution d’un programme. Il est donc malvenu de mapper l’intégralité des tableaux de données présents dans la mémoire du PC en utilisant la pinned memory, surtout qu’à part pour les transferts CPU / GPU, il n’y a aucun gain de performances qui en découle.
SPEAR connaît, à partir du graphe d’application mappée sur l’architecture, les tableaux qui vont être utilisés pour transférer des données vers/depuis le GPU. Les allocations en pinned memory sont automatiquement réalisées pour (et uniquement pour) ces tableaux.
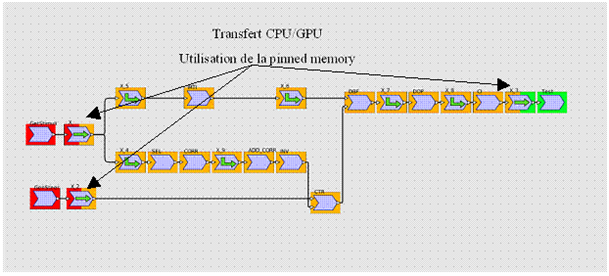
Figure 20: utilisation de la pinned memory dans l'application
3.3.1.4. Utilisation de plusieurs queues de commande
Un contrôleur DMA est une ressource programmable, comme tout autre processeur, avec la différence qu’elle est spécialisée dans le mouvement de données. Le langage OpenCL permet de programmer ce contrôleur DMA distinctement du GPU. Il faut pour cela utiliser une autre queue de commande, différente de celle utilisée pour lancer les calculs.
Ainsi les tâches de communication (transfert de données) utiliseront une queue de commande, alors que les tâches de calculs en utiliseront une autre. Sur la Figure 20, les tâches bicolores X_, X_2 et X_3 (représentant les communications) seront donc sur une command queue différente du reste des tâches oranges (représentant les tâches de calcul sur GPU). Sur cet exemple, la communication X_ est visiblement nécessaire avant toute autre tâche sur GPU, à cause des dépendances de données. Par contre X_2 peut se faire en même temps qu’une partie des tâches de calculs sur GPU puisque les données transférées par X_2 ne seront utilisées que par CTR. En même temps que X_2, neuf autres tâches peuvent être exécutées, et la communication est complètement masquée au niveau temporel.
Le risque d’utiliser plusieurs command queues est le même que lorsque le mode « out of order » est actif : il faut s’assurer que la communication est bien terminée avant de démarrer une tâche de calcul qui en dépend, ou vice-versa. L’utilisation des events OpenCL est donc nécessaire.
L’exemple de la Figure 21 montre que l’utilisation d’une seule command queue impose l’exécution séquentielle de chaque tâche, et le temps d’exécution total est au moins égal à la somme du temps d’exécution de chaque tâche. Ici le temps d’exécution est supérieur ou égal à T1+T2+T3.
L’utilisation d’une autre command queue lève cette contrainte. Par contre, l’utilisation de plusieurs queues impose des synchronisations locales (events) pour conserver l’ordonnancement et donc garder un code fonctionnel (la tâche bleue doit attendre que la tâche verte soit terminée avant de commencer). La deuxième communication n’a visiblement aucune conséquence au niveau du temps d’exécution global, et donc le temps d’exécution est supérieur ou égal à T1+T3 seulement.
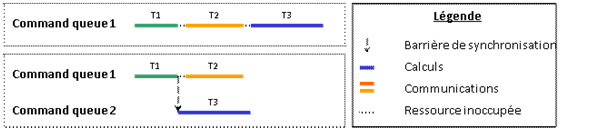
Figure 21: utilisation de plusieurs queues de commande
Certaines cartes professionnelles Nvidia (Tesla, Quadro) permettent d’utiliser la particularité du bus PCI Express, qui permet de travailler en Full Duplex (même s’il est plus correct de dire que les cartes « grand public » sont bridées de manière logicielle par Nvidia au niveau des pilotes). Il faut alors utiliser trois command queues : une pour les calculs, une pour les communications dans un sens et une dernière pour les communications dans l’autre sens, puisque trois tâches peuvent s’exécuter en parallèle avec ces cartes.
SPEAR affecte automatiquement les différentes tâches (calculs, communications) aux command queues associées, de manière à pouvoir en effectuer plusieurs en parallèle (si l’ordre de précédence le permet).
3.3.2. Optimisation selon l’architecture cible
SPEAR permet la sélection de l’architecture cible, à partir de la plateforme et du type de périphérique utilisé. Cette sélection se fait par le modèle d’architecture intégré de SPEAR, et lors de la phase de déploiement de l’application sur les ressources de calculs (phase de segmentation).
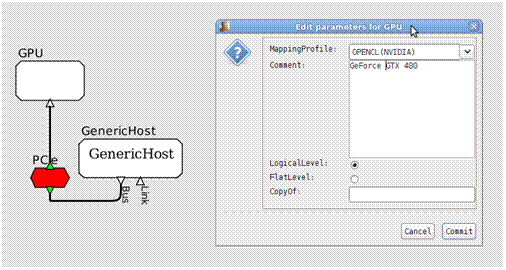
Figure 22: exemple de modèle d'architecture SPEAR
Lors de la sélection de la plateforme utilisée, l’utilisateur a plusieurs choix possibles :
- il sélectionne la plateforme (AMD, Nvidia, Intel, etc…) à utiliser, mais laisse le programme déterminer la ressource de calcul la plus puissante à disposition sur cette plateforme au moment de l’exécution pour réaliser les calculs. Le programme est davantage portable, mais selon les périphériques installés, les performances pourront fortement varier.
- il sélectionne la plateforme à utiliser, et force le périphérique à utiliser en spécifiant son nom dans le modèle d’architecture. Dans ce cas, si le périphérique désigné n’est pas présent, le programme ne pourra pas s’exécuter et une erreur sera levée.
3.3.2.1. Génération de code spécifique à la plateforme
Une fois le modèle d’architecture désigné pour exécuter l’application, SPEAR peut générer du code OpenCL. Cependant, certaines primitives ou certaines optimisations sont plus efficaces que d’autres selon les constructeurs, le type de ressource (qui peut être GPU, CPU, Accélérateur, etc…) puisqu’OpenCL est un langage standard applicable à de nombreuses architectures parallèles. En fonction de la ressource choisie, le code généré peut être plus ou moins différent, l’objectif étant d’avoir le code le plus performant possible pour la cible voulue.
En fonction des implémentations OpenCL et des ressources utilisées, ces optimisations peuvent évoluer au cours du temps. L’utilisation d’un outil comme SPEAR permet à l’utilisateur de générer le code optimal pour la plateforme voulue sans posséder une connaissance pointue de l’architecture.
3.3.2.2. Génération de code pour plusieurs périphériques, homogènes ou non
Une des difficultés du langage OpenCL est l’utilisation de plusieurs périphériques, de manière à réaliser du parallélisme de tâche et/ou de données sur plusieurs GPUs (lorsque cela est possible). La figure suivante montre un modèle d’architecture avec deux cartes Geforce GTX 480, utilisables en parallèle.
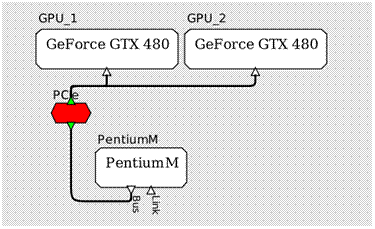
Figure 23: modèle d'architecture multi-gpus
SPEAR est un outil initialement destiné à faciliter le parallélisme (de tâche ou de données) sur des architectures possédant plusieurs ressources de calcul. Le fait que ces ressources soient en fait des GPUs avec des centaines de processeurs élémentaires ne change pas la fonctionnalité première de SPEAR. Il est donc naturel de pouvoir utiliser plusieurs GPUs en parallèle, qui effectueront chacun des milliers d’opérations également en parallèle, sur une partie des données. Le découpage se fait grâce à quelques clics de souris (et ce, que les GPUS soient identiques ou non) de la même plateforme ou d’une autre.
Un point dur reste pourtant : l’impossibilité d’utiliser de la « pinned memory » pour plusieurs périphériques en même temps, ce qui peut diminuer les vitesses des communications. Cependant, l’utilisation de plusieurs GPUs se fait dans le cas d’applications lourdes, où les communications représentent normalement un faible pourcentage du temps d’exécution total. Cette limitation ne devrait pas avoir un gros impact.
3.3.2.3. Gridification
Many-core et Multiprocesseurs
L’une des particularités des many-cores actuels est la répartition des processeurs élémentaires en groupes, appelés multiprocesseurs. Ces multiprocesseurs possèdent une mémoire partagée commune à tous les processeurs contenus dans ce multiprocesseur, et invisible pour les autres processeurs du many-core.
Ce découpage au niveau hardware a un impact sur la programmation des GPUs.
Notions de work-item/workgroup :
La méthode de programmation des GPUs est de répartir un ensemble de tâches à réaliser (organisées en nid de boucles) sur les centaines de processeurs disponibles sur la puce. Afin de permettre la répartition de toutes ces tâches à exécuter (appelées work-items), elles sont regroupées en workgroup (qui peut ne contenir qu’un seul work-item), et chaque workgroup est exécuté par un seul et unique multi-processeur (qui peut, lui, exécuter plusieurs workgroups séquentiellement).
Il est important de bien "découper" l’application en workgroups pour obtenir de bonnes performances.
Explication de la problématique par un exemple d’application
Une carte Nvidia GTX 550 Ti (GPU) possède 192 processeurs regroupés en multiprocesseurs comportant 48 processeurs ; elle a donc 4 multiprocesseurs de 48 processeurs.
Pour traiter une image de 1024x768 pixels, un exemple de traitement possible est de consommer l’intégralité d’une ligne (1024 pixels). Il faut donc répéter ce traitement 768 fois pour traiter l’image complète. Sur la GTX 550 Ti, si les workgroups sont fixés avec une taille de 128, cela fera 768/128 = 6 workgroups de 128 lignes à traiter, et à répartir sur les 4 multiprocesseurs.
Donc 2 des 4 multiprocesseurs auront 1 workgroup à traiter, et 2 des 4 multiprocesseurs en auront 2.
Comme il faut attendre la fin du traitement de tous les multiprocesseurs pour passer à l'opération suivante, un nombre de workgroups non multiple du nombre de multiprocesseurs peut déjà avoir un impact sur les performances.
A l’intérieur du multiprocesseur, un workgroup de 128 lignes est aussi problématique dans cet exemple. Le multiprocesseur comporte 48 processeurs, et donc les 128 lignes d'un workgroup doivent être réparties, ce qui fait 128/48 = 2.66 traitements par processeur.
A l'intérieur d'un même multiprocesseur, certains processeurs vont traiter 2 lignes, et d'autres 3.
Comme la synchronisation se fait à la fin du traitement de tous les processeurs d’un multiprocesseur, il faut attendre la fin du travail des processeurs qui traitent 3 lignes, et ceux qui n’en traitent que 2 restent inoccupés pendant le traitement de la dernière ligne, ce qui fait perdre de la puissance de calcul.
Avec des workgroups de 192 lignes au lieu de 128, chaque multiprocesseur doit traiter 1 workgroup. De même, un workgroup de 192 lignes est multiple de 48, donc chaque processeur va traiter 192 / 48 = 4 lignes.
Comparaison des deux découpages :
- workgroup 128: certains processeurs traitent 3 lignes dans chaque multiprocesseur, et certains multiprocesseurs traitent 2 workgroups ; donc certains processeurs vont traiter 6 lignes au total.
- workgroup 192: tous les processeurs d'un multiprocesseur traitent 4 lignes, et chaque multiprocesseur traite 1 workgroup ; donc tous les processeurs traitent 4 lignes.
Dans cet exemple, passer d’une taille de workgroup de 128 à 192 permet de gagner 50% en performance.
Cette répartition a donc une très forte influence sur les performances globales obtenues au final. Comme certaines applications ont beaucoup de kernels différents, ou utilisent les mêmes avec des données de taille différente, c'est un système souvent complexe à résoudre, puisque les répartitions sont (le plus souvent) nettement plus complexes à déterminer que dans l’exemple.
SPEAR propose deux gridifications automatiques possibles :
- une gridification basique, prenant en compte la plateforme d’exécution et le nombre de work-items à réaliser (plus rapide à obtenir et fonctionnelle, généralement pour la mise au point),
- une gridification optimisée (recherche de performances pures), qui sera détaillée ultérieurement.
3.3.3. Aide au débogage et au profiling
Le retour d’expérience montre qu’avant d’avoir un code avec un bon facteur d’accélération, il faut initialement effectuer un portage fonctionnel sur GPU, afin de valider l’application sur GPU. Une fois ce portage effectué, l’optimisation peut être réalisée.
3.3.3.1. Aide au débogage
Un point dur de ce portage est qu’il est impossible, sans outillage adapté, de debugger directement les kernels OpenCL puisque les outils de debug classiques ne peuvent pas accéder directement à l’espace mémoire du GPU (mémoire globale). Certaines applications le permettent, mais sont disponibles sous Windows uniquement, ou bien sont payantes.
L’outil SPEAR génère du code avec des portions de code réservées à l’aide au débogage. Lorsque le code est produit, un Makefile associé est généré également, avec des options désactivées par défaut. Une de ces options permet de récupérer tous les tableaux intermédiaires, restant normalement dans la mémoire globale, dans la mémoire centrale du PC, puis de sauvegarder ces résultats dans des fichiers ou de les comparer avec des valeurs de référence.
Cette fonctionnalité proposée à chaque génération de code permet de gagner beaucoup de temps dans la mise en œuvre d’une application sur GPU.
3.3.3.2. Aide au profiling
SPEAR propose deux fonctionnalités qui peuvent être utiles au développeur sur GPU.
La première est une option proposée dans le fichier Makefile, qui permet de tracer (lors de l’exécution) la durée d’une fonction exécutée sur GPU en mesurant - sur le host - le temps écoulé entre l’envoi de la fonction dans la command queue associée, et la réalisation de cette fonction sur le GPU. Cette mesure comprend donc l’overhead potentiel de l’appel, le temps d’exécution et le temps de synchronisation du CPU par le GPU. La mise en œuvre de cette fonctionnalité, puisqu’elle se déroule sur le host, impose un fonctionnement synchrone du GPU. Elle est utile pour avoir un aperçu clair et rapide du temps passé dans chaque fonction (identification du hotspot par exemple).
La deuxième permet d’analyser plus finement ce qui se passe sur l’accélérateur. La spécification du langage OpenCL propose des fonctions permettant de connaître précisément le moment du passage de la commande dans la command queue, le moment où la commande a été émise vers le GPU, le moment du début du travail et celui de sa fin. Ces fonctions s’appuient sur les « events », qui servent également à la synchronisation des tâches en mode asynchrone et qui sont déjà générés par SPEAR.
L’outil SPEAR propose de récupérer ces events dans un fichier Excel afin de réaliser un profiling de chaque kernel exécuté sur le GPU.
Si certains constructeurs proposent des outils permettant de faire la même chose, ces outils sont différents pour chaque architecture. Les données fournies par SPEAR sont par contre les mêmes, quelle que soit la cible d’exécution.
3.4. Génération de kernels
Pour l’instant, SPEAR ne propose pas de transformation automatique d’une fonction C en kernel GPU. Ce portage se fait manuellement, et le plus souvent, une simple adaptation des fonctions existantes permet d’avoir un code fonctionnel sur GPU, et qui permettent d’atteindre une accélération notable.
Voici un exemple de code existant (nid de boucles) :

Figure 24: nid de boucles en C
Dans cette fonction, le noyau atomique est la soustraction d’un nombre complexe par un autre nombre complexe. Il faut donc itérer bSize x bSize fois pour consommer l’intégralité des données en entrée. Le déplacement dans les matrices d’entrée et de sortie s’effectue selon i et j, les indices de boucles.
Voici la version OpenCL de la fonction Subtract :

Figure 25: version OpenCL
Dans ce cas de figure, les boucles internes de la fonction n’apparaissent plus dans le kernel, mais sont externalisées de manière à pouvoir être réparties sur les multiprocesseurs de l’architecture. Il ne reste que le cœur de la fonction, et une formule qui permet de retrouver la position des différentes valeurs dans les matrices d’entrées/sorties.
3.5. Processus de portage de code
Selon la complexité de l’application et la personne qui la réalise, l’expérience a montré que cette étape peut varier de plusieurs jours à plusieurs semaines. En effet, l’écriture du code « host », très verbeux, est laborieux à écrire et est source d’erreur. Et comme le « host » met en œuvre des kernels sur le périphérique OpenCL, dans le cas d’un résultat faux, l’erreur peut venir de l’écriture du code « host » comme de celle du code « kernels ».
L’utilisation de SPEAR présente un avantage : à partir d’un graphe d’application, l’outil va générer un code « host » fonctionnel. Grâce à cela, le développeur réalisant le portage n’a plus qu’à se concentrer sur le portage des kernels. Comme les kernels possèdent le plus souvent un faible nombre de lignes, cela peut se faire assez rapidement.
Pour faciliter la validation des résultats intermédiaires (situés dans la mémoire globale du GPU), un flag de compilation permet de récupérer tous les tableaux de la mémoire globale vers la mémoire du PC, et de les écrire dans un fichier pour les consulter par la suite, ou les comparer avec des valeurs de référence afin d’effectuer une validation automatique. Cette fonctionnalité couplée avec la précédente permet efficacement d’écrire, de tester le fonctionnement et de valider les résultats de chaque kernel dans leur ordre d’utilisation dans l’application.
Cette mise en œuvre a permis de porter très rapidement des applications existantes sur GPU, parfois en moins d’une journée, puisque le seul travail à fournir est l’écriture puis la validation des kernels exécutés sur GPU ; le reste du travail étant automatisé.
3.6. Processus d’optimisation de code
3.6.1. Optimisation côté « host »
L’outil SPEAR permet de générer du code OpenCL « host », sans erreur et qui met en œuvre les différentes optimisations présentées précédemment. Ces optimisations sont effectuées à chaque génération de code OpenCL, et ne nécessitent pas d’intervention de l’utilisateur.
Les sections suivantes décrivent d’autres optimisations qui découlent du choix de l’utilisateur parce que, contrairement aux précédentes, ces optimisations ne sont pas toujours applicables.
3.6.1.1. Gridification optimisée
On a vu que le découpage a une importance capitale pour obtenir de bonnes performances. En effet, un même kernel réparti de manière inadéquate par le code « host » entraine des performances lamentables, parfois pires que lorsque le code n’est pas parallélisé.
Trouver le bon découpage apportant la meilleure performance est souvent une affaire d’expérience du développeur, qui doit connaître l’architecture cible, et de la réalisation d’une série de tests. Et ce découpage « optimal » doit être effectué pour chaque kernel de l’application afin que la mauvaise performance d’un seul ne dégrade pas la performance globale de l’ensemble.
De plus, lorsque l’utilisateur modifie le fonctionnement d’un kernel ou le remplace par un autre, il faut de nouveau lui trouver le découpage optimal. Ce processus peut parfois être long, et est souvent fastidieux.
SPEAR propose une fonctionnalité qui permet, pour une application et des kernels donnés, de déterminer, avec une probabilité extrêmement forte, le découpage optimal pour chaque kernel de l’application, et ce, pour chaque périphérique OpenCL utilisé (même dans le cadre d’une application multi-gpus).
Le seul pré-requis pour l’utilisation de cette fonctionnalité est la génération de code sur une plateforme possédant un GPU identique à celui servant de cible finale. Cette fonctionnalité a fait l’objet d’un dépôt de brevet.
3.6.1.2. Software pipelining
Même avec l’optimisation des transferts CPU / GPU (maximisant la bande passante), le temps de communication reste, dans les applications embarquées temps réel, une partie importante du temps d’exécution ; et le recouvrement de certaines communications par des calculs n’est pas toujours possible ou suffisant.
Il existe cependant une solution pour minimiser le temps de communication/calcul au plus long des deux, en forçant le recouvrement. Ce forçage est possible grâce à une fusion de boucles, dont le principe est expliqué ci-dessous.
Notion de fusion
Une fusion est une répétition d’un travail sur des données différentes afin de permettre de découper un gros traitement (sur une importante quantité de données) en plusieurs traitements plus petits, traitant seulement une partie du jeu de données. Ainsi, au lieu de transférer l’intégralité des données sur GPU, puis d’effectuer le traitement global et enfin de récupérer les résultats pour les exploiter avec le CPU, un découpage est réalisé (en respectant la dépendance de données) de manière à ne traiter qu’un n-ième des données, et à répéter ce traitement n fois (voir Figure 26).
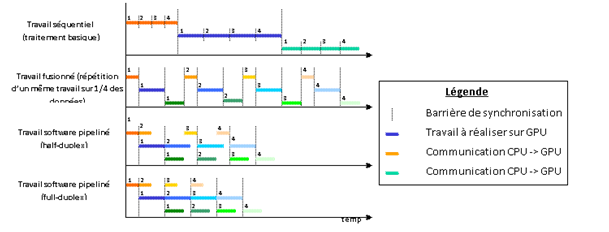
Figure 26: exemples de fusions
Il est possible, dans l’interface de SPEAR, de sélectionner les différentes tâches à fusionner, de manière à découper le traitement en plusieurs parties. A partir de cette fusion, SPEAR va générer le code qui permet ce « software pipelining », et donc ce gain en performance.
3.6.2. Profiling d’application
Une fois les kernels existant et le code « host » optimisé, il peut être intéressant d’effectuer un « profiling » d’application afin de savoir précisément le temps passé par chaque kernel exécuté sur le GPU et quel pourcentage du temps global de l’application ce temps représente.
Parfois, certains kernels, même s’ils sont très mal écrits ou très peu parallélisés, sont très peu représentatifs dans le temps global de l’application. Il est tout à fait inutile de chercher à les améliorer puisque cette amélioration sera quasi-invisible au niveau des performances globales.
De même, un kernel peut représenter à lui seul une part importante de l’application. Il est donc intéressant de passer du temps à améliorer son comportement et donc son temps d’exécution, ce qui aura un impact notable sur le temps d’exécution global de l’application. Certaines méthodes pour améliorer les kernels sont décrites dans la dernière sous-section.
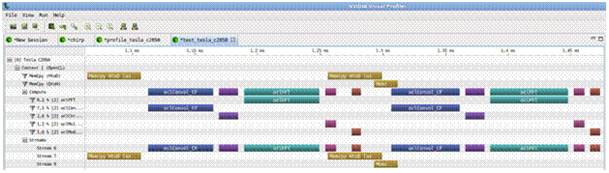
Figure 27: profiler NVIDIA
Le temps passé à optimiser un kernel peut être un bon investissement car, contrairement au code « host » ultra-spécifique à une application donnée, les kernels sont souvent réutilisés d’une application à l’autre. Le travail fait une fois ne sera pas à refaire par la suite, il sera capitalisé dans une bibliothèque de fonctions.
Le profiling peut être réalisé soit par un outil tiers (souvent un outil fournir par un constructeur pour ses architectures, comme celui de Nvidia Figure 27), soit par SPEAR qui peut fournir les informations de profiling dans un fichier Excel, utilisable pour n’importe quelle architecture.
3.6.3. Optimisation côté « kernels »
L’optimisation des kernels ne peut se faire de manière automatique puisque certaines optimisations sont vraiment spécifiques au cas d’utilisation et à l’application.
Cependant, certaines règles sont applicables de manière générale :
- éviter les branchements (if, switch/case, etc…) car cela peut pénaliser nettement les performances (temps d’exécution multiplié par le nombre de branches existantes dans un workgroup),
- essayer d’avoir une bonne localité, car comme les accès à la mémoire globale d’un kernel sont nettement plus coûteux que des calculs, il vaut mieux éviter les allers-retours mémoire globale / registres si c’est possible,
- quand c’est possible, l’utilisation de la mémoire partagée des multiprocesseurs peut également éviter des accès à la mémoire globale,
- externaliser les tours de boucle présent dans la fonction à exécuter de manière à ce que ces boucles apparaissent au niveau de la grid, pour multiplier les combinaisons de répartition de charge des multiprocesseurs et être certain de trouver la taille de workgroup optimale,
- essayer de faire lire et écrire les kernels dans la mémoire globale de manière séquentielle, de manière à éviter des transferts mémoire supplémentaires et coûteux (coalescing),
- dans certains cas, le déroulage de boucles ou la mise en avant de certaines fonctions vectorielles peuvent apporter des informations supplémentaires qui permettent au compilateur de mieux optimiser le code.
L’application des optimisations décrites ici, couplées aux optimisations au niveau « host », permettent d’atteindre sans trop d’effort de bonnes performances, même par un développeur qui connaît peu l’architecture cible.
Parfois un kernel pose problème car il est faiblement ou pas parallélisable. Il faut alors prendre une décision :
- si le coût des communications rend possible son exécution sur CPU, c’est peut-être la meilleure solution (sinon c’est rédhibitoire),
- il faut peut-être réécrire le kernel de manière à mettre en évidence le parallélisme qui n’est pas évident au premier abord.
Ce cas de figure nécessite par contre une expertise au niveau parallélisme ainsi qu’une connaissance des architectures many-core pour obtenir un kernel efficace.
Points importants :
- OpenCL étant un standard qui se développe de plus en plus, les constructeurs proposent le plus souvent des kernels déjà optimisés pour leur architecture, rendant inutile tout portage manuel ou toute optimisation. Egalement, de plus en plus de fonctions sont disponibles sur le net, et une communauté se développe autour de ce langage.
- Le coalescing est très important pour les GPUs ne possédant pas de cache de données. Cependant les nouvelles générations de GPUs proposent une mémoire cache qui permet d’être moins sensible au coalescing. Grâce à cela, l’écriture des kernels se trouve facilitée.
4. Conclusion
Le couplage PIPS / SPEAR permet d’extraire automatiquement les paramètres de parallélisme et des informations de placement de l'application sur machine parallele : SPEAR présente le code pour favoriser au maximum l’analyse de dépendances par PIPS et PIPS renvoie à SPEAR les paramètres en question.
Cette approche complémentaire qui mixe des outils de parallélisation automatique et semi-automatique apporte un gain certain en vue d’obtenir du code OpenCL performant. Elle permet ainsi d’explorer plusieurs schémas de parallélisation.
Document Actions